
.png)
OpenTelemtry概览
首先我们要认识到,目前所设计的一整套体系都是为了构建可观测性。
不管是使用老牌工具zabbix,skywalking或者是otel,grafana。工具只是手段,目的是为了让我们能更了解我们的系统
什么是可观测性
可观测性是描述我们对系统中所发生情况的理解程度,比如 我的系统正常运行还是已停止? 、 终端用户察觉到变快还是变慢? 、我们应建立哪些 KPI 和 SLA(SLA 是一种双方的约定,是一种服务可用性的指标)以及如何了解它们是否符合这些指标? 等等情况,我们需要能够回答像这样的各种运行和业务问题,需要能够在问题出现时指出问题(理想的情况是在其中断客户体验之前),快速地响应,并尽可能快速地解决。为了获得这种洞察力,我们就需要可观测的系统。
学术界一般会将可观测性分解为三个更具体方向进行研究,分别是:事件日志、链路追踪和聚合指标,这三个方向各有侧重,又不是完全独立,它们天然就有重合或者可以结合之处。
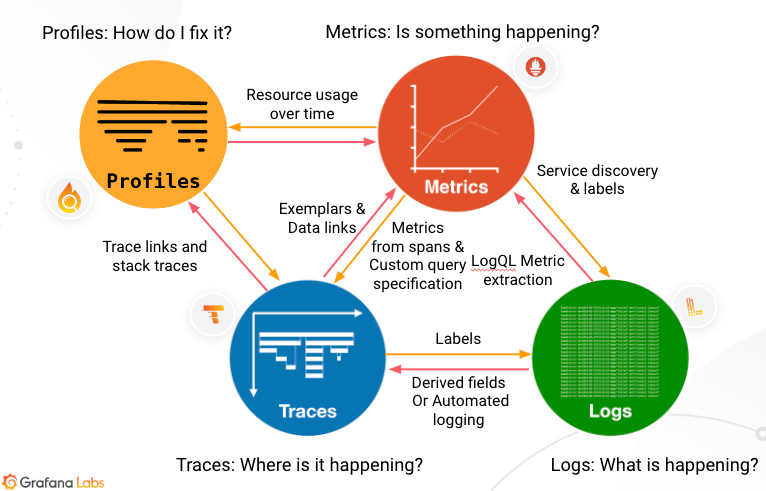
在云中,由于系统极其复杂,可能难以保证可观测性,但无论是在数据中心还是在云中,为了实现卓越运营和业务目标,我们都需要了解系统的运行情况。可观测性解决方案使我们能够收集和分析来自应用程序和基础设施的数据,以便了解它们的内部状态,并就应用程序可用性和性能问题获得警示,排查故障并予以解决,从而改善终端用户体验。
假如你平时只开发单体系统,从未接触过分布式系统的观测工作,那看到日志、追踪和指标,很有可能只会对日志这一项感到熟悉,其他两项会相对陌生。尽管分布式系统中追踪和指标必要性和复杂程度确实比单体系统时要更高,但是在单体时代,实际上你肯定也已经接触过以上全部三项的工作,只是并未意识到而已:
- 日志(Logging) :日志的职责是记录离散事件,通过这些记录事后分析出程序的行为,譬如曾经调用过什么方法,曾经操作过哪些数据,等等。打印日志应该算是程序中最简单的工作之一,调试问题时常有人会说“当初这里记得打点日志就好了”,可见这就是一项举手之劳的任务。输出日志的确很容易,但收集和分析日志却会很复杂,面对成千上万的集群节点,面对迅速滚动的日志信息,面对数以 TB 计算的文本,传输与归集都并不简单。对大多数程序员来说,分析日志也许就是最常遇见也最有实践可行性的“大数据系统”了。
- 追踪(Tracing) :单体系统时代追踪的范畴基本只局限于堆栈的追踪(Stack Tracing),调试程序时,在 IDE 打个断点,看到的 Call Stack 视图上的内容便是追踪;编写代码时,处理异常调用了
Exception::printStackTrace()方法,它输出的堆栈信息也是追踪。微服务时代,追踪就不只局限于调用栈了,一个外部请求需要内部若干服务的联动响应,这时候完整的调用轨迹将跨越多个服务,同时包括服务间的网络传输信息与各个服务内部的调用堆栈信息,因此,分布式系统中的追踪在国内常被称为****全链路追踪 ,许多资料中也称它为 分布式追踪 。追踪的主要目的是 排查故障 ,如分析调用链的哪一部分、哪个方法出现错误或阻塞,输入输出是否符合预期,等等。 - 指标(Metrics) :指标是指对系统中某一类信息的统计聚合。譬如,证券市场的每一只股票都会定期公布财务报表,通过财报上的营收、净利、毛利、资产、负债等等一系列数据来体现过去一个财务周期中公司的经营状况,这便是一种信息聚合。Java 天生自带有一种基本的指标,就是由虚拟机直接提供的 JMX(Java Management eXtensions)指标,诸如内存大小、峰值的线程数、垃圾收集的吞吐量、频率等等。指标的主要目的是监控和预警,如某些指标达到风险阈值时触发报警,以便自动处理或者提醒管理员介入。
目前针对可观测性的产品已经是一片红海,经过多年的角逐,日志和指标这两个领域的胜利者算是基本尘埃落定。日志收集和分析大多被统一到 Elastic Stack(ELK)技术栈上,对于云原生时代,可能会将其中的 Logstash 用 Fluentd 取代,让 ELK 变成 EFK,但整套 Elastic Stack 技术栈的地位相对比较稳固,当然现在也出现了类似于 Grafana Loki 和基于 ClickHouse 的日志系统,对 Elastic Stack 技术栈有不少冲击。
对于指标方面,随着 Kubernetes 成为容器编排领域的标准,Prometheus 也击败了指标领域里以 Zabbix 为代表的众多前辈,成为了云原生时代指标监控的事实标准,虽然从市场角度来说 Prometheus 还没有达到 Kubernetes 那种举世无敌的程度,但是从社区活跃度上看,Prometheus 已占有绝对的优势,Kubernetes 是 CNCF 第一个孵化毕业的项目,Prometheus 是 CNCF 第二个毕业的项目。
追踪方面的情况与日志和指标有所不同,追踪是与具体网络协议、程序语言密切相关的,收集日志不必关心这段日志是由 Java 程序输出的还是由 Golang 程序输出的,对程序来说它们就只是一段非结构化文本而已,同理,指标对程序来说也只是一个个聚合的数据指标而已。但链路追踪就不一样,各个服务之间是使用 HTTP 还是 gRPC 来进行通信会直接影响追踪的实现,各个服务是使用 Java、Golang 还是 Node.js 来编写,也会直接影响到进程内调用栈的追踪方式。这决定了追踪工具本身有较强的侵入性,通常是以插件式的探针来实现;也决定了追踪领域很难出现一家独大的情况,通常要有多种产品来针对不同的语言和网络。近年来各种链路追踪产品层出不穷,市面上主流的工具既有像 Datadog 这样的商业方案,也有 Google Stackdriver Trace 这样的云计算厂商产品,还有像 SkyWalking、Zipkin、Jaeger 这样来自开源社区的优秀产品。

由 OpenTracing 进化而来的 OpenTelemetry 融合了日志、追踪、指标三者所长,有望成为三者兼备的统一可观测性解决方案。
什么是 OpenTelemetry
为了使微服务系统能够可观察,必须对其进行检测。也就是说,代码必须发出追踪、指标和日志。然后必须将经过检测的数据发送到可观察性后端。过去,检测代码的方式会有所不同,因为每个可观察性后端都有自己的检测库和代理,用于向工具发送数据。
这意味着没有用于将数据发送到可观察性后端的 标准化数据格式 。此外,如果一家公司选择切换观测后端,这意味着他们不得不重新检测他们的代码并配置新代理,以便能够将遥测数据发送到新选择的工具。
由于缺乏标准化,最终结果是 缺乏数据可移植性和用户维护代码的高成本 。
认识到标准化的必要性后,云社区聚集在一起,诞生了两个开源项目:OpenTracing(云原生计算基金会 (CNCF) 项目)和 OpenCensus(Google 开源社区项目)。
OpenTracing提供了供应商中立的 API,用于将遥测数据发送到可观察性后端;但是,它依赖于开发人员实现自己的库来满足规范。OpenCensus提供了一组特定于语言的库,开发人员可以使用这些库来检测他们的代码并发送到他们支持的任何一个后端。
为了统一标准,OpenCensus 和 OpenTracing 在 2019 年 5 月合并成立了 OpenTelemetry(简称 OTel),作为 CNCF 的孵化项目,OpenTelemetry继承了两者的优点,并且做了更进一步的优化。
OTel的目标是提供一套标准化、与厂商无关的 SDK、API 和工具集,用于将数据摄取、转换和发送到可观测性后端(开源或商业厂商)。
OpenTelemetry 可以做什么?
OTel 拥有来自云提供商、供应商和最终用户的广泛行业支持和采用。它可以为我们提供:
- 每种语言都有一个单一的、与供应商无关的检测库,支持自动和手动检测。
- 一个独立于供应商的收集器二进制文件,可以通过多种方式进行部署。
- 一个端到端的实现,用于生成、发出、收集、处理和导出遥测数据。
- 完全控制你的数据,能够通过配置将数据并行发送到多个目的地。
- 开放标准的语义约定,以确保与供应商无关的数据收集
- 能够并行支持多种上下文传播格式,以协助随着标准的发展进行迁移。
通过支持各种开源和商业协议、格式和上下文传播机制以及提供 OpenTracing 和 OpenCensus 项目的 shim 垫片,因此很容易使用 OpenTelemetry。
但是也需要注意 OpenTelemetry 不是像 Jaeger 或 Prometheus 那样的可观察性后端,即 OpenTelemetry 不提供与可观测性相关的后端服务,这类后端服务通常提供的是存储、查询、可视化等服务。相反,它支持将数据导出到各种开源和商业后端。它提供了可插拔的架构,因此可以轻松添加其他技术协议和格式。